
What is React-Redux? An introduction – Redux
Quick Summary: In this blog, we will understand the concept of React-Redux. Readers can get a solid understanding of how it facilitates efficient state management in JavaScript applications.
Introduction
Several front-end libraries are becoming increasingly popular worldwide, but React is the most prevalent. Companies like Airbnb, Netflix, and The New York Times, from startups to top-notch, embrace these platforms to create enticing and interactive applications.
JavaScript apps use React-Redux to maintain predictable states. When an application grows, it becomes increasingly more work to maintain and keep data flow organized. React-Redux comes into play here.
This article will help developers create apps with Redux practices and help you better understand React-Redux to find the right React.native for you.
What is Redux?
Redux is a popular and predictable state management library often used in front-end development. Furthermore, it integrates with React to build interactive and elegant user interfaces for the application. By centralizing the state of an application, developers can monitor the changes in the application and maintain a predictable flow of data.
Additionally, it follows the flux architecture pattern and user action, reducers, and a store to manage and update application data.
When to use Redux?
Redux is useful when developers need to handle large-scale state management in React apps. Furthermore, It’s beneficial in scenarios where the state is shared across multiple components and requires consistent updates.
Additionally, it streamlines tracking changes and eases debugging and data flow. Thus, making it suitable for building complex applications with intricate state interactions is required.
Core concepts of Redux
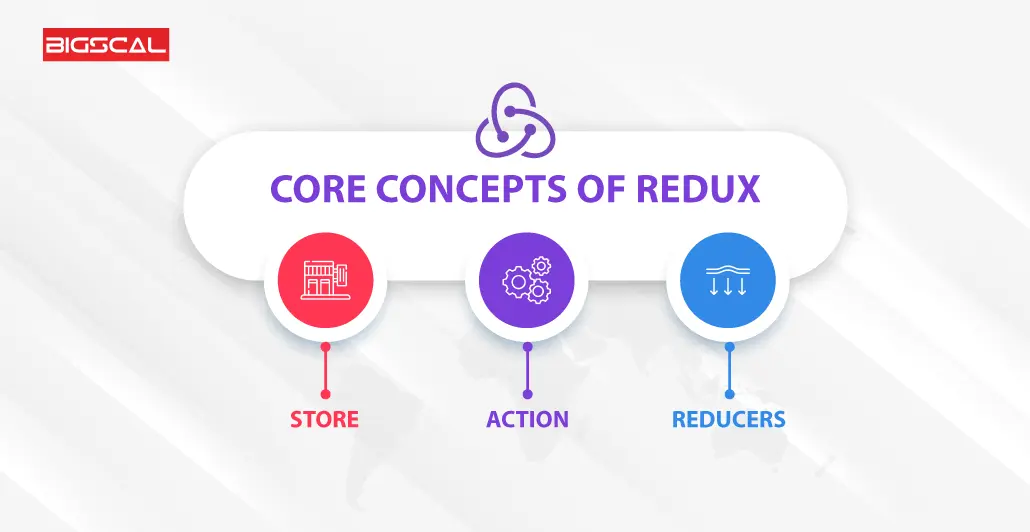
To understand the concepts of React-Redux, developers must learn the core concept of Redux. It includes three principles:
1. Store
A store is an object that describes the application state tree. In other words, a store is a giant container that comprises all the application data. Additionally, it leverages reducers, manages state updates, provides a way to access the state, and dispatches actions.
2. Action
Redux action is a JavaScript object describing what type of action is performed. Furthermore, they are data payloads that send information from applications to storage.
3. Reducers
Reducers are pure functions that define how the application state changes. Furthermore, it helps developers determine store updates by processing the current state and the action.
Advantages of Using React-Redux
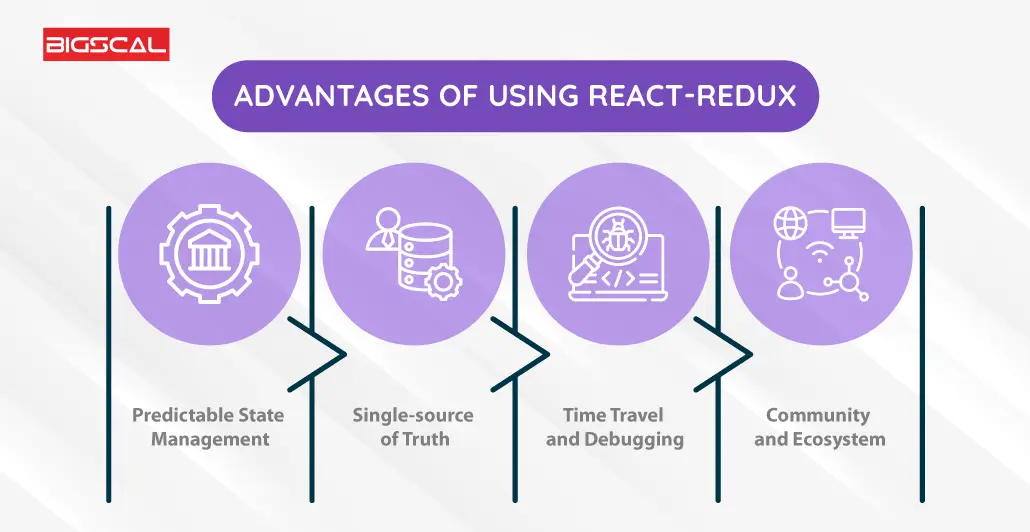
React-redux offers several benefits:
1. Predictable State Management
Redux follows unidirectional data flow that helps developers predict the changes and streamlines the code debugging.
2. Single-source of Truth
All data across all the components is stored in a single repository. Thus, it eases data synchronization and management.
3. Time Travel and Debugging
By leveraging Redux’s time-traveling debugger, developers can replay past actions and check the state at any point in the development process.
4. Community and Ecosystem
Redux has a massive community of developers and encloses a vast ecosystem of tools, middleware, and extensions.
Getting Started with React-Redux
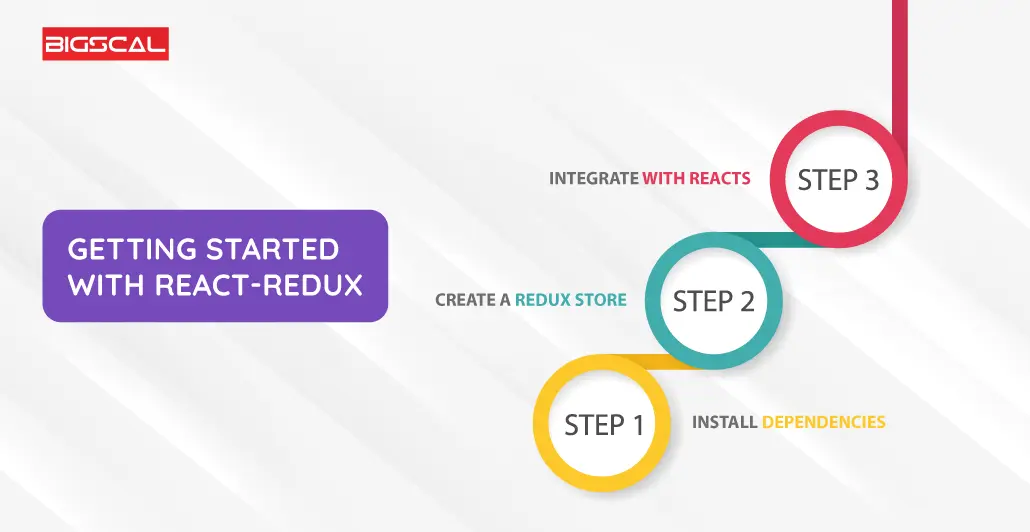
Getting started with React-Redux consists of the following steps:
Step 1: Install Dependencies
The first step is to install the packages you need: redux, react-redux, and any additional middleware that might be required.
Step 2: Create a Redux Store
Create the Redux store, which will store the state of the application. You can define reducers to handle specific aspects of the state.
Step 3: Integrate with React
The application can access the Redux store across all components by leveraging the React-Redux Provider component.

Setting Up Redux in a React Application
To set up Redux in a React application:
1. Create a store
Using Redux, create a store function, create a store. Furthermore, make use of combineReducers if necessary to combine reducers. Additionally, describe the store’s initial state.
2. Create Reducer
Create reducers, update the state, and handle different actions as required.
3. Provider component
Provide access to the Redux store by wrapping your main application component in the Provider component.
4. Actions and Action Creators
Actions are objects written in Javascript that describe changes to the state in Redux. Furthermore, Action creators are functions that return these action objects to trigger state updates. By encapsulating the process of creating actions, errors can be avoided.
5. Reducers and Store
A reducer specifies how the state of an application changes as a result of user action. The new state is based on the previous state and the action dispatched. Additionally, leveraging the store will help you to modify and access the components in the application state.
6. Connecting React Components to Redux Store
React-Redux’s connect function allows components to connect to the Redux store. As a result of this connection, components can access the Redux state and enable them to initiate state changes by dispatching actions accordingly.
7. Middleware in Redux
During the dispatch of an action, middleware sits between it and the moment of dispatch to the reducer. Additionally, it provides the capability to log, make asynchronous API requests, and dispatch multiple actions simultaneously.
8. Async Operations with Redux
Redux middleware, such as redux-saga or redux-thunk, allows developers to handle the asynchronous operations. Furthermore, Async operations help in scenarios like fetching data from an API.
9. React-Redux Hooks
UseSelector and useDispatch hooks in React-Redux simplify connecting components to the store. Compared to the traditional connect function, hooks provide a more concise way to access state and dispatch actions.

Common Mistakes to Avoid with Redux
Excessive Nesting: Developers should avoid using excessive nesting of components in the application to prevent complexity from arising.
Overusing State: It is unnecessary to store all the states in Redux. Furthermore, developers should use a local component state for non-shared data.
Not Normalizing Data: Developers must normalize the complex structures to enhance the application’s performance and avoid redundant updates.
Testing Redux Applications: It is necessary to test actions, reducers, and components when testing Redux applications. It is possible to write comprehensive tests using libraries like redux-mock-store and react-testing-library.
Conclusion
Hopefully, the above blog provides a concise explanation of the React-Redux concept. It aims to enhance your understanding of how it manages state in Javascript applications, offering insights into its fundamental principles and functionality.
FAQ
What is Redux JS?
The React Redux Framework is a Javascript library for managing the state of the React Redux application. Furthermore, it includes a centralized store and enables predictable updates through actions and reducers.
What is Redux state management?
Redux state management React includes a valuable library for designing Javascript applications. Furthermore, it provides a centralized store to manage the application state, making it predictable and easy to manage.
What is state management React-redux?
A state management system facilitates communication and data sharing across components. In this way, the state of your app can be represented in a tangible data structure.
What is the React logo?
The React-Redux logo combines React’s logo (a blue square with React in white) and the Redux logo (a circular emblem with “Redux” in blue). Furthermore, it symbolizes their integration for efficient state management in React applications.
Why do you need Redux state management?
State management is one of the vital components of creating an application. Furthermore, it centralizes all the application state control to handle the data flow across the application. Additionally, it is a powerful feature that allows you to organize your knowledge base sections by remembering their state.

