
Top 10 Tips to Improve SQL Query Performance
Quick Summary: This article delves into ten important things to do if one seeks to boost the performance of SQL queries, the audience to expect are beginners and experts in the field alike. The declaimer goes on to describe the performance analytics section to reduce query execution time, reduce resource consumption, and to improve database performance through indexing techniques, highlighting how indexes store data in one or more columns to facilitate quick data retrieval, searching for queries intelligently, and maintaining janitorial database tasks. They can consequently enable the developers to straightforward query studies of relational databases and subsequently unlock their full potential.
Introduction
SQL job is super fun to do when you have references to the best tricks and tools to make it happen effectively. Long list of his details looks more like a warning to me… details like him working in shifts, his personality type, what time he wakes up in the morning; it feels like I am being told to be ready for something…
SQL tuning is a hard nut to crack. One cannot avert such unwanted effects by a single simple change in the performance. It also covers optimizing both, query, index, and server configurations in order to boost the database performance and responsiveness.
Microsoft SQL Server offers various query optimization tools and best practices that can significantly enhance database performance.
Working together with the custom software solution providers improves SQL query efficiency via optimizing properly, methods, indexing, query tuning and management database techniques.
If you are a beginner in SQL, writing SQL queries can be daunting tasks, so just be patient and never stop reading all the way through.
In this post, we will explain to you some techniques to help you improve SQL statements efficiency, how to achieve performance tuning in SQL, how to refine and optimize sql query, query optimization techniques and we will explore Python database connection
How to Check SQL Server Query Performance: Step-by-Step Guide:
Viewing SQL Queries is a task in itself. There are certainly many factors to keep in mind when testing humans in the same way. However, the steps to follow are important. The steps to follow to learn how to optimize sql server performance and check query performance in SQL Server are as follows:
Enabling the Query Store:
Step 1: Move to SQL Server management and open it. One can use the query store feature of sql server performance improvement techniques to monitor the performances of the database available. If you have the SQL server before 2016, you need to enable it manually.
Step 2: move to object explorer. A user can locate the option by clicking View Menu at the top of the screen and then hitting “Object. Explorer”
Step 3: The list of databases will appear here. A user needs to select the database they want to work with. After that, click on “Properties.”
Step 4: Hit on the Query Store option that appeared. After that, Select “On” under ″Operation Mode (Requested). After doing this, all the queries will be detected.
Step 5: Finally, refresh the database in the Object Explorer panel. Within a while, you will see the query folder added to the panel.
Step 6: Now, how you wish to customize the data is on you. By default, every 60 minutes, new stats get aggregated by the Query Store. If you want, you can change the interval for it as well.
SQL Performance Tuning: 7 Practical Tips for Developers
SQL performance tuning is an essential aspect of database development that focuses on optimizing the execution speed and efficiency of SQL queries. Improving SQL performance can significantly enhance the application’s speed and responsiveness, leading to a better user experience. Here are a few practical tips for developers to achieve SQL performance tuning.
Use Indexes Wisely:
An index is a data structure that efficiently finds and retrieves database rows. Properly chosen indexes can speed up SELECT, UPDATE, and DELETE operations. However, excessive or inappropriate indexing can slow down write operations. As a result, it creates indexes on columns utilized in WHERE clauses and JOIN conditions by analyzing query patterns. Avoid making too many indexes, especially on columns with low selectivity. Indexes store data in one or more columns to facilitate quick data retrieval.
Optimize Your Queries:
Developers should carefully design SQL queries to be efficient and use the database’s full potential. Avoid using SELECT * and, instead, specify only the necessary columns. Minimize subqueries or correlated subqueries, as they can be performance bottlenecks. Based on the data relationship, use appropriate JOIN techniques (INNER JOIN, LEFT JOIN, etc.).
Be Cautious with Joins and Subqueries:
Joins and subqueries are quite expensive in terms of time and effort, that is, they depend on the amount of data. Then one must incorporate good JOIN conditions, and make sure that written subqueries are properly optimized. One consideration is that neither subqueries nor nested subqueries are particularly efficient, and so it is ideal to work towards minimizing the use of the latter entirely.
Limit the Result Set:
It is wise to pull only the data that one requires to analyze or to be used in the application. If your query would produce thousands of rows try to use the LIMIT clause for reducing the count to desired amount. However, applying filters (using the WHERE clause) or limiting the number of records returned using the use of a pagination system will further restrict the data received. In addition, it reduces the number of messages exchanged between the application and database, enhancing efficiency.
Appropriately Size and Configure the Database:
It is also important to see that bits of information are sized and set up adequately to help the load it has to process. Optimize the amount of memory allocated in a virtual environment and other matching parameters of required memory, cache and buffer pool in accordance with the obtained quantity of available CPU and RAM, as well as the expected amount of query load. Database performance monitoring analysis is significantly beneficial to developers, as it requires them to check for troubles.
Batch Operations:
One of the things that one has to bear in mind is the fact that whenever carrying out repetitive tasks, it is more efficient to use batch processes, instead of subjecting the data to individual SQL statements. Subqueries, on the other hand, are expensive in terms of number of connections and therefore not suitable for batch operations Although subqueries can be very handy for inserting values into one table but the values come from another table, batch operations are much better for Insert, Update, or Delete operations.
Avoid Cursors:
Cursors Are used to traverse through the rows in a result set, basically they are very time consuming Cursors are beneficial but at the same time costlier. In addition, developers can utilize the set based operations rather than using the cursor to work on values.
Regularly Update Statistics:
In DBMS, a statistics maintained that allows the optimization of the execution of a query. It is also necessary to update statistics on tables and indexes in a timely manner, so that the query optimizer could make a correct decision as to the optimal execution plan for a query.
Monitor and Fine-tune:
Controlling & optimizing of SQL queries can be a process of evaluating, applying of monitoring as well as profiling tools in order to discover slow or frequently executed queries. Optimize queries for performance, by regularly scrutinizing the query execution plans, knowing the SQL query performance issues, and the settings that can be tweaked.
Tips to Improve SQL Query Performance
Guidelines for improving slow SQL Query performance: principles of SQL query optimization. Let’s have a look,
Do Not Use in select statement for criteria selection. If we use then it will retrieve all the columns of a specific table and consumes time whereas using the desired column name is always efficient.
Do Not Use * In Select Statment.
If we use * then it gives all columns of the particular table and it takes time so that’s why it’s better to use the column name which is required for the result.
Example:-
SELECT *
FROM Department - - - Bad Parctice
SELECT Id,DeptName,Description
FROM Department - - - Good Practice
Use Exists instead of Sub Query
If sometimes need to use subquery at that time first use Exist() function of the SQL server only when the subquery returns large data. In this case, Exist() function works faster than In because Exist() function returns a boolean value based on the query.
Example:-
SELECT Id, Name
FROM Employee
WHERE DeptId In (SELECT Id
FROM Department
WHERE Name like ‘%Management%’) - - - Bad Practice
SELECT Id, Name
FROM Employee
WHERE DeptId Exist (SELECT Id
FROM Department
WHERE Name like ‘%Management%’) - - - Good Practice
Use Proper join instead of subqueries
It’s better to use join instead of subquery because based on join like left or right query only checks that records which are matched with criteria while in subquery they check all records and then return result so it’s time-consuming that’s why in this case use proper join as per requirement.
Example:-
SELECT Id, Name
FROM Employee
WHERE DeptId in (SELECT Id
FROM Department
WHERE Name like ‘%Management%’) - - Bad Practice
SELECT Emp.Id, Emp.Name,Dept.DeptName
FROM Employee Emp
RIGHT JOIN Department Dept on Emp.DeptId = Dept.Id
WHERE Dept.DeptName like ‘%Management%’ - - - Good Practice
Use “Where” instead of “Having” a clause
Here if we use “WHERE” then it will check in all records with the specific condition while if we use “HAVING” at that time user must need to apply “GROUP BY” and through the “GROUP BY” all data are displayed in group-wise and then after “HAVING” clause find the data from only that grouping which are filtered by “GROUP BY“, that’s why it’s executing fastly compare to “WHERE” while any table has much more data. This is a common SQL query optimization technique.
“Group by“, that’s why it’s executing fastly compare to “Where” while any table has much more data.
Example:-
SELECT Emp.Id, Emp.Name,Dept.DeptName,Emp.Salary
FROM Employee Emp
RIGHT JOIN Department Dept on Emp.DeptId = Dept.Id
WHERE Emp.Salary >= 20000; - - Good Practice
SELECT Emp.Id, Emp.Name,Dept.DeptName,Emp.Salary
FROM Employee Emp
RIGHT JOIN Department Dept on Emp.DeptId = Dept.Id
GROUP BY dept.DeptName
HAVING Emp.Salary >= 20000; - - - Bad Practice
Apply index on necessary columns
An index creates a unique data column without overlapping each other. It improves the speed of data retrieval. While applied index on that time its work like as per the below diagram.
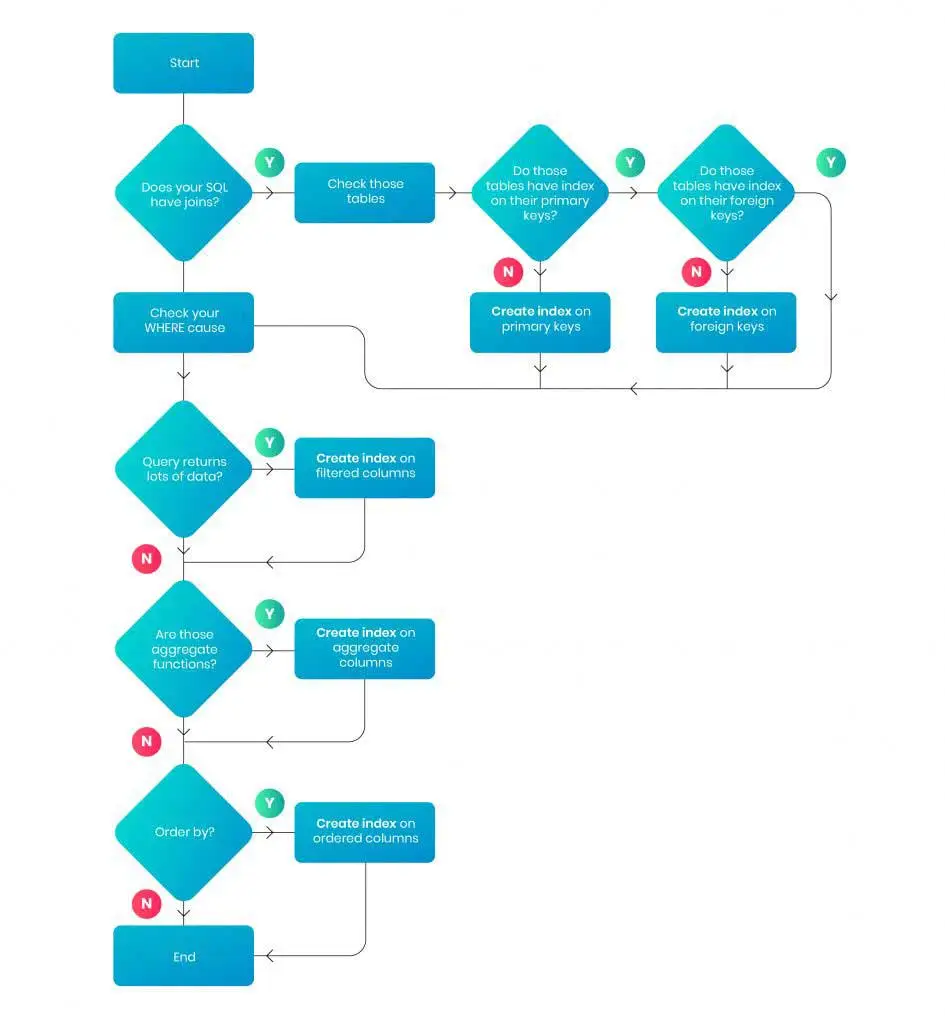
For user-defined stored procedures avoid prefixes like “sp_”
As in SQL databases, the master database has some inbuild stored procedures which are starting with “sp_” so whenever we create a user-defined stored procedure at that time we can avoid prefixes like “sp_” because when we use that stored procedure in our code at that time SQL first finds from master database and it takes some extra time that’s why if we give another name instead of “sp_” then it will take less time.
Apply UNION ALL instead of UNION if possible
The major difference between UNION and UNION ALL is that UNION returns distinct records while UNION ALL returns all records including duplicates. Using UNION ALL instead of UNION is a common SQL query optimization technique because it avoids the overhead of sorting and removing duplicates, which can significantly improve database performance and reduce costs. While we apply UNION on that time function first apply sort and then find the distinct record and then return a result that’s why it takes more time to compare to UNION ALL. As if we require only distinct records at that time we can use UNION.
Example:-
- If table Employee have following records
- Ramesh
- Mahesh
- Sita
- Nita
- Naresh
- If table Employee_new have the following records
- Sita
- Gita
- Ramesh
- While we apply UNION at that time queries like:
- SELECT * FROM Employee
UNION
SELECT * FROM Employee_new
- SELECT * FROM Employee
- Result:-
- Ramesh
- Mahesh
- Sita
- Nita
- Naresh
- Gita
- While we apply UNION ALL at that time queries like:
- SELECT * FROM Employee
UNION ALL
SELECT * FROM EMployee_new
- SELECT * FROM Employee
- Result:-
- Ramesh
- Mahesh
- Sita
- Nita
- Naresh
- Sita
- Gita
- Ramesh
Avoid Negative search
As we know sometimes users are using negative search in where conditions like not equals (<>), not like, etc. but we need to avoid that type of search because if we give the exact search criteria on that time while query executing if that type of data is got then immediately query returns the result. Negative searches decrease the query execution speed that’s why we need to avoid that.
Avoid query in a loop
If sometimes we need to execute the same query multiple times like if we need to insert 10 records in any table at that time don’t use insert query in the loop instead of using bulk insert.
Example:-
For(Int i = 0;i <= 5; i++)
{
INSER INTO Table1(Id,Value) Values( i , ‘Value’ + i );
} - - - Bad Practice
INSERT INTO Table1(Id, Value)
Values(1,Value1),(2,Value2),(2,Value3),(4,Value4),(5,Value5) - - - Good Practice
Apply valid datatype on the column
As we know sometimes some new users do not know the actual use of datatype and they all apply varchar datatype for all columns but it’s not the right way, as per client requirements we need to identify first which type of data is required and based on that need to apply proper datatype.
Example:-
- In the Isdelete column, we need to set only boolean (true, false) value if the record is deleted or not.
- In the Creation Date column, we need to set the DateTime datatype.
- If the Department column is used as the foreign key in any table at that time we need to store that department’s id only not a name so we can set Integer datatype.
How do you find SQL developers for your project?
When checking out SQL efficiency, it is essential to have a team of experienced SQL Server consultants available. If the experienced team is not available, one will not be able to figure out whether things are going in the right direction. Well, the factors that you need to keep in mind include.
Knowledge of software development in general:
The primary factor that is important to look out for includes their knowledge of software development. If they are aware of basic SDLC, there is a point in hiring them. Some instances are there where it is essential that, along with SQL query, they also have good hands-on experience in the software development life cycle. If you feel like they need more knowledge, look for someone else. Make sure not to settle for less while hiring the developer.
Able to maintain database security:
Database security is a challenge to maintain. Several tools, tricks, and techniques are essential to adapt to the same. Ask the developer about the securities that they are using. If they cannot maintain database security, they are not the ones with whom you can connect long-term. For long-term collaboration, clarity must be available regarding the tools and methods they adopt for database security. As soon they figure out that this will work in this way, then only the developers can be finalized.
You can also inform them about the tools you consider for database security. This will help you know whether they can align themselves with the same. If there is anything that you find suspicious, drop the idea and look for someone else for the same. A clear discussion will help get the best services.
Able to work with SQL environment:
The candidate’s proficiency in working with the SQL (Structured Query Language) environment is important to know. SQL query is a programming language that helps developers to manage and manipulate databases. The SQL developer should be familiar with writing SQL queries to retrieve, insert, update, and delete data from databases. They should be comfortable navigating through different database management systems (DBMS) like MySQL, PostgreSQL, SQL Server, Oracle, etc. Look for candidates who have practical experience in handling complex queries, optimizing database performance, and understanding database schemas
Cost for the project:
The cost for the project is the financial aspect of hiring the SQL developer. It involves negotiating and determining the remuneration or contract rate for the services provided by the developer. When evaluating the cost, consider the developer’s skills, experience, and the complexity of the project. A highly skilled and experienced developer may demand higher compensation, but they might also deliver better results in less time. On the other hand, hiring a less experienced developer might save money initially, but it could lead to longer development times and potentially subpar outcomes.
Time required for delivery:
The estimated timeframe the SQL developer requires to complete the project successfully is also essential. Assess the candidate’s ability to set realistic timelines and deliver projects on time. Look for developers who have experience in project management, understand the scope of work, and can provide a detailed timeline for different project milestones. A reliable and punctual developer is crucial to ensure that the project meets its deadlines and doesn’t face unnecessary delays.
How are they handling deadlines:
The candidate’s approach to managing and meeting project deadlines is something that one cannot overlook. An excellent SQL query developer should demonstrate a track record of meeting project timelines and delivering results within the agreed-upon timeframes. They should have strong organizational and time management skills to handle multiple tasks efficiently. Additionally, the developer should be proactive in communicating any potential delays or roadblocks that might impact the project’s progress.
Understanding of latest SQL query updates:
As technology evolves, SQL query is subject to updates and enhancements. A proficient SQL developer should keep up-to-date with the latest SQL query updates, new features, and improvements in database management systems. This ensures they can leverage the most current and efficient techniques in their work. During the hiring process, inquire about the candidate’s awareness of recent SQL query advancements, and ask them how they stay informed about changes in the SQL landscape.
Able to work with a dedicated team:
Being able to work effectively in a dedicated team is crucial for successful project execution. A good SQL developer should have strong communication skills and the ability to collaborate with other team members, including project managers, other developers, and stakeholders. Teamwork is essential for problem-solving, sharing knowledge, and delivering a cohesive final product. During the hiring process, look for candidates who can demonstrate their experience working in team environments and handling team-based projects.
Conclusion
In conclusion, working with SQL is fun. A developer needs to be sure of all the tips and tricks that they can follow to make things work. Developers should thoroughly understand query optimization SQL servers techniques. If you are someone who is working with SQL or want to know more about it, this read is best to consider. For sure after keeping all these parameters in mind you can get the best outputs as needed!
FAQ
Why is SQL query performance important?
SQL query performance directly impacts the responsiveness and efficiency of your application. Faster queries mean reduced user wait times and improved user experience, making it crucial for any database-driven application.
What are some common factors affecting SQL query performance?
Common factors include a need for proper indexing, inefficient query design, large data sets, poorly written queries, and suboptimal database configuration.
Is it essential to regularly update statistics and indexes to maintain SQL query performance?
Yes, regularly updating statistics and indexes is vital. Outdated statistics can lead to poor query plans, while well-maintained indexes improve query execution speed and overall database performance.
Can denormalization improve query performance in SQL?
Yes, denormalization can enhance query performance in some cases. By reducing JOINs and data retrieval complexity, denormalization can speed up queries. However, it may lead to data integrity and maintenance challenges, so it should be carefully implemented.
How do you combine multiple tables in SQL?
In SQL, multiple tables can be combined using JOIN statements to retrieve data from related tables based on common columns, enabling complex queries and data analytics.
How can query runtime be optimized to improve SQL query performance?
Query runtime can be optimized by monitoring performance metrics to detect issues, using proper indexing, and refining query design. Specific SQL tips, such as avoiding SELECT *, using JOINs efficiently, and breaking down complex queries, can significantly reduce query runtime and improve overall performance.

